
The command line can be a daunting place for beginners. It requires a fair bit of memorization and typing to navigate. However, it can also be incredibly powerful. If you’re unfamiliar with the command line interface, you might find it difficult to grep content from files. That’s where Cut commands come in. These tools let you quickly cut text out of a file. They’re especially useful when you want to grep columns in a file. What’s more, they’re easy to learn and master.
In this article, we’ll show you how to use the Cut command in Linux. We’ll also show you some useful tips and tricks along the way. So, if you’re new to Linux, this is the guide for you!
cut [option] [filename]
Options
The options are combined with commands to perform certain tasks. There are various options that can be used with the cut command, a list of commonly used options are given below:
- ‘-f’ to cut by fields
- ‘-b’ to cut by byte positions
- ‘-c’ to cut by characters
- ‘-d’ to specify a delimiter
We also have to provide a filename to cut/extract portions based on the specified option.
Cut the bytes
The first option we will discuss is “-b”. This option can be used to extract particular bytes. “-b” option needs to be followed with a list of bytes separated by a comma. You can also give the “-b” option a range of bytes using a hyphen.
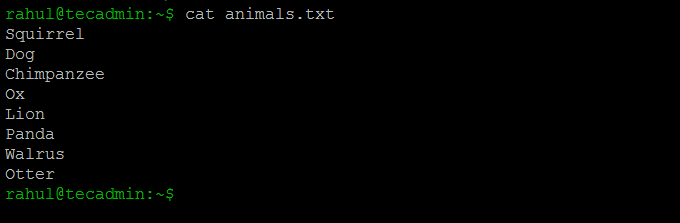
Now we will use the “cut” command on a file named “animals.txt” as an example. This file contains the names of different animals. We can check the content of a text file by using the following command:
cat animals.txt
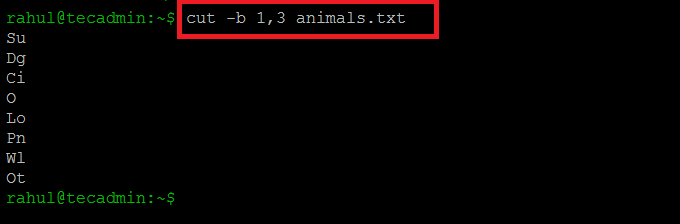
Now we will try to output only the first and the third byte of each line in the text file by using the following command:
cut -b 1,3 animals.txt
Cut the Characters
Before we move any further first let me explain the difference between a byte and a character.
One byte has 8 bits that can represent 256 different values. As the computers became more global and accessible, the language which had more than 256 characters made it impossible to do one-to-one mapping. So a new Unicode UTF-8 was created.
The old ASCII standard had 128 characters. Each character was represented by a single byte. However, in UTF-8 characters are represented by 1 to 4 bytes. Tabs and spaces are considered as a character of one byte.
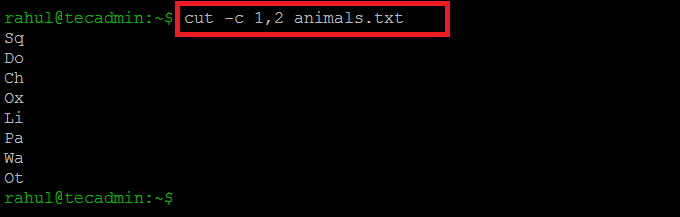
Now let’s try to output the first two characters of the file “animals.txt”
cut -c 1,2 animals.txt
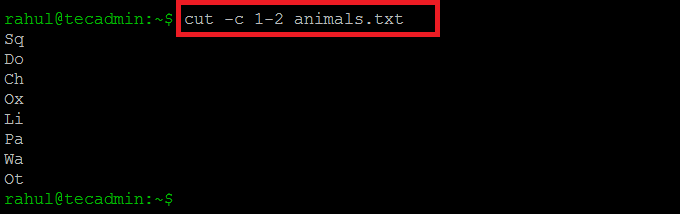
We can also write “1,2” as a sequence of characters:
cut -c 1-2 animals.txt
Cut by fields
We can use the “-f” option along with the “cut” command to extract a particular field. We can also combine the “-d” option with “-f” to define a delimiter. The delimiter specifies where a field ends. The default delimiter is “TAB”.
Now we will use the “numbers.txt” file as an example. This file contains a sequence of numbers with semi-colons separated by “TAB”.
We will use the following command to output the first and third files of the text file:
cut -f 1,3 numbers.txt

Now we will use the “-d” option to change the delimiter. We can set any character as a delimiter but here we will set the “;” as the delimiter:
cut -f 1,3 -d ';' numbers.txt

Using compliment with Cut
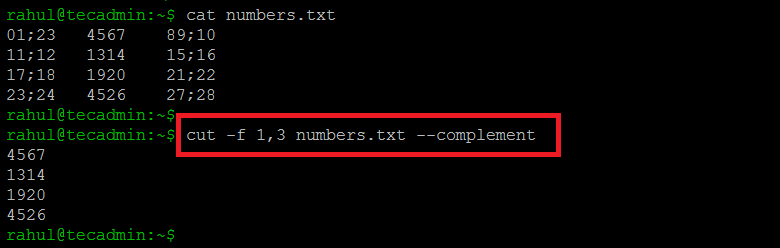
We can also use “--compliment” to extract and print everything except the fields selected by the “-f” option:
cut -f 1,3 numbers.txt --complement
Conclusion
“cut” is a command-line utility used to extract fields from each line of a file or standard input based on specified criteria. It is a very convenient and powerful tool.
In this write-up, we have learned what the “cut” command is and how to use it with different options. We have also discussed some useful examples of the “cut” command.

: Opportunities and Challenges")