Bash is one of the most popular shells and is used by many Linux users. One of the great things you can do with Bash is removed duplicate lines from files. It’s a great way to declutter a file and make it look cleaner and more organized. This can be done with a simple command in the Bash shell.
All you have to do is type in the command “sort -u” followed by the name of the file. This will take the file and sort the content, then use the command “uniq” to remove all duplicates. It’s an easy and efficient way to remove duplicate lines from your files. If you’re a Linux user, this is a great tool to have in your arsenal. So the next time you need to clean up a file, give this Bash command a try and see how it works for you!
Removing Duplicate Lines from File
To remove duplicate lines from a file in bash, you can use the sort and uniq commands.
Here is an example of how to do it:
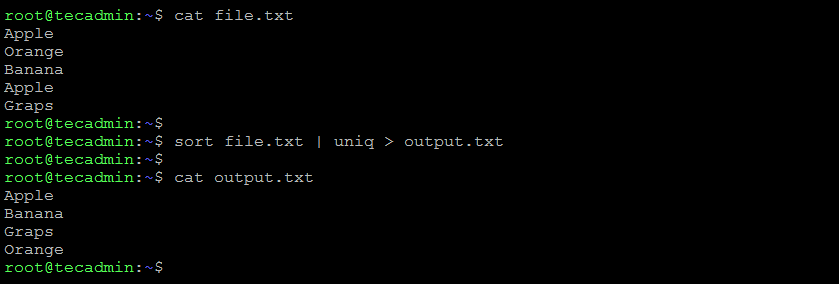
sort file.txt | uniq > output.txt
This will sort the lines in file.txt, remove the duplicates, and save the result to a new file called output.txt.
You can also use the -u option of the sort command to achieve the same result:
sort -u file.txt > output.txt
If you want to remove the duplicates in-place, without creating a new file, you can use the tee command to redirect the output back to the original file:
sort file.txt | uniq | tee file.txt[OR] sort -u file.txt | tee file.txt
Keep in mind that these commands will only remove duplicates if the lines are exactly the same. If you want to ignore leading or trailing white space, or case differences, you can use the -i, -b, and -f options, respectively. For example:
sort -f -u file.txt > output.txt
This will remove duplicates, ignoring case differences.
sort -f -b -u file.txt > output.txt
This will remove duplicates, ignoring case differences and leading/trailing white space.