Apache Hadoop 2.6.5 noticeable improvements over the previous stable 2.X.Y releases. This version has many improvements in HDFS and MapReduce. This how-to guide will help you to install Hadoop 2.6 on CentOS/RHEL 7/6/5, Ubuntu and other Debian-based operating system. This article doesn’t include the overall configuration to setup Hadoop, we have only basic configuration required to start working with Hadoop.

Step 1: Installing Java
Java is the primary requirement to setup Hadoop on any system, So make sure you have Java installed on your system using the following command.
#java -version java version "1.8.0_101 " Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
If you don’t have Java installed on your system, use one of the following links to install it first.
Install Java 8 on CentOS/RHEL 7/6/5
Install Java 8 on Ubuntu
Step 2: Creating Hadoop User
We recommend creating a normal (nor root) account for Hadoop working. So create a system account using the following command.
# adduser hadoop # passwd hadoop
After creating an account, it also required to set up key-based ssh to its own account. To do this use execute following commands.
# su - hadoop $ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
Let’s verify key based login. Below command should not ask for the password but the first time it will prompt for adding RSA to the list of known hosts.
$ ssh localhost $ exit
Step 3. Downloading Hadoop 2.6.5
Now download hadoop 2.6.0 source archive file using below command. You can also select alternate download mirror for increasing download speed.
$ cd ~ $ wget http://www-eu.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz $ tar xzf hadoop-2.6.5.tar.gz $ mv hadoop-2.6.5 hadoop
Step 4. Configure Hadoop Pseudo-Distributed Mode
4.1. Setup Hadoop Environment Variables
First, we need to set environment variable uses by Hadoop. Edit ~/.bashrc file and append following values at end of file.
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Now apply the changes in current running environment
$source ~/.bashrc
Now edit $HADOOP_HOME/etc/hadoop/hadoop-env.sh file and set JAVA_HOME environment variable. Change the JAVA path as per install on your system.
export JAVA_HOME=/opt/jdk1.8.0_131/
4.2. Edit Configuration Files
Hadoop has many of configuration files, which need to configure as per requirements to setup Hadoop infrastructure. Let’s start with the configuration with basic Hadoop single node cluster setup. first, navigate to below location
$ cd $HADOOP_HOME/etc/hadoop
Edit core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Edit hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Edit mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Edit yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.3. Format Namenode
Now format the namenode using the following command, make sure that Storage directory is
$hdfs namenode -format
Sample output:
15/02/04 09:58:43 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = svr1.tecadmin.net/192.168.1.133 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.5 ... ... 15/02/04 09:58:57 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted. 15/02/04 09:58:57 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 15/02/04 09:58:57 INFO util.ExitUtil: Exiting with status 0 15/02/04 09:58:57 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at svr1.tecadmin.net/192.168.1.133 ************************************************************/
Step 5. Start Hadoop Cluster
Now start your Hadoop cluster using the scripts provides by Hadoop. Just navigate to your Hadoop sbin directory and execute scripts one by one.
$ cd $HADOOP_HOME/sbin/
Now run start-dfs.sh script.
$start-dfs.sh
Sample output:
15/02/04 10:00:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-namenode-svr1.tecadmin.net.out localhost: starting datanode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-datanode-svr1.tecadmin.net.out Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. RSA key fingerprint is 3c:c4:f6:f1:72:d9:84:f9:71:73:4a:0d:55:2c:f9:43. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts. 0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-secondarynamenode-svr1.tecadmin.net.out 15/02/04 10:01:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Now run start-yarn.sh script.
$start-yarn.sh
Sample output:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-resourcemanager-svr1.tecadmin.net.out localhost: starting nodemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-nodemanager-svr1.tecadmin.net.out
Step 6. Access Hadoop Services in Browser
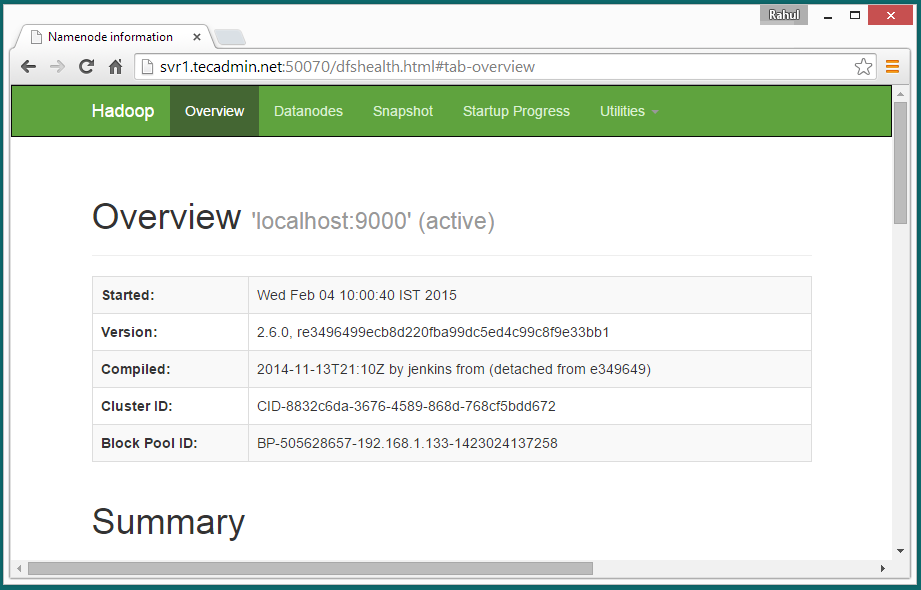
Hadoop NameNode started on port 50070 default. Access your server on port 50070 in your favorite web browser.
http://svr1.tecadmin.net:50070/
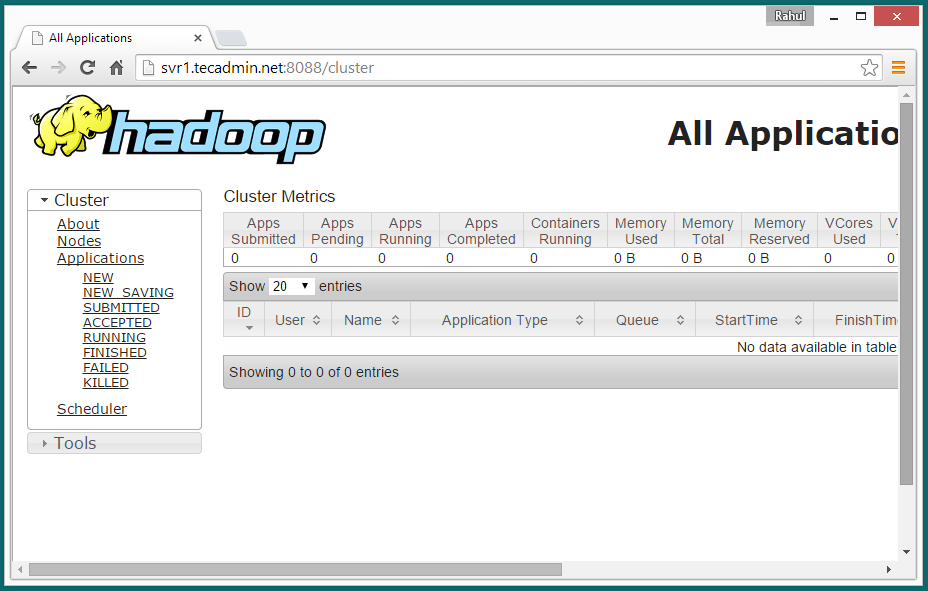
Now access port 8088 for getting the information about cluster and all applications
http://svr1.tecadmin.net:8088/
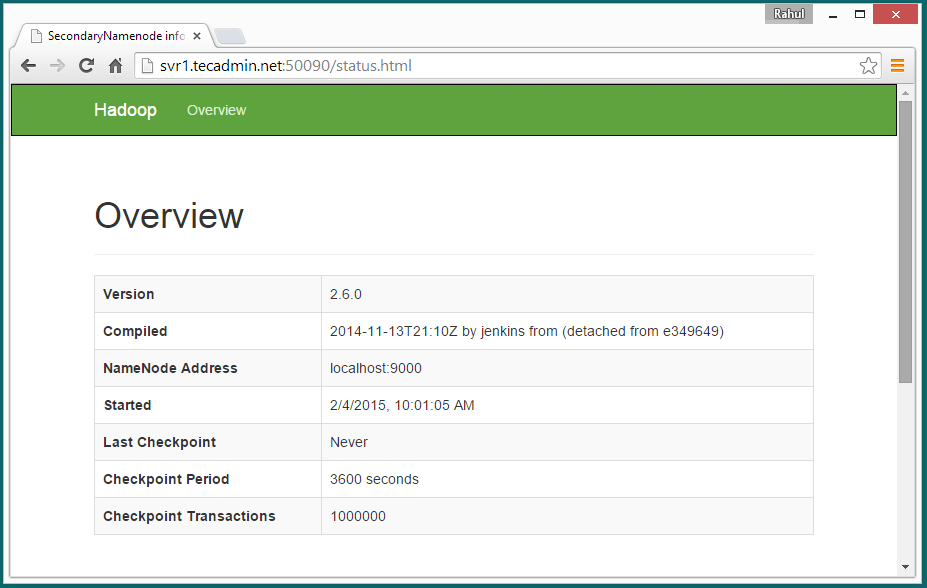
Access port 50090 for getting details about secondary namenode.
http://svr1.tecadmin.net:50090/
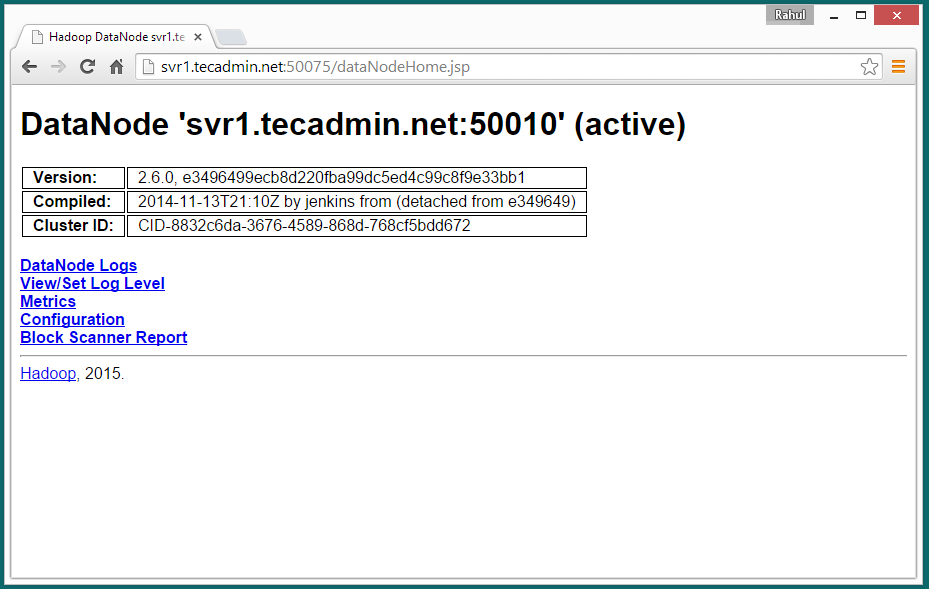
Access port 50075 to get details about DataNode
http://svr1.tecadmin.net:50075/
Step 7. Test Hadoop Single Node Setup
7.1 – Make the HDFS directories required using following commands.
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/hadoop
7.2 – Now copy all files from local file system /var/log/httpd to hadoop distributed file system using below command
$ bin/hdfs dfs -put /var/log/httpd logs
7.3 – Now browse hadoop distributed file system by opening below url in browser.
http://svr1.tecadmin.net:50070/explorer.html#/user/hadoop/logs
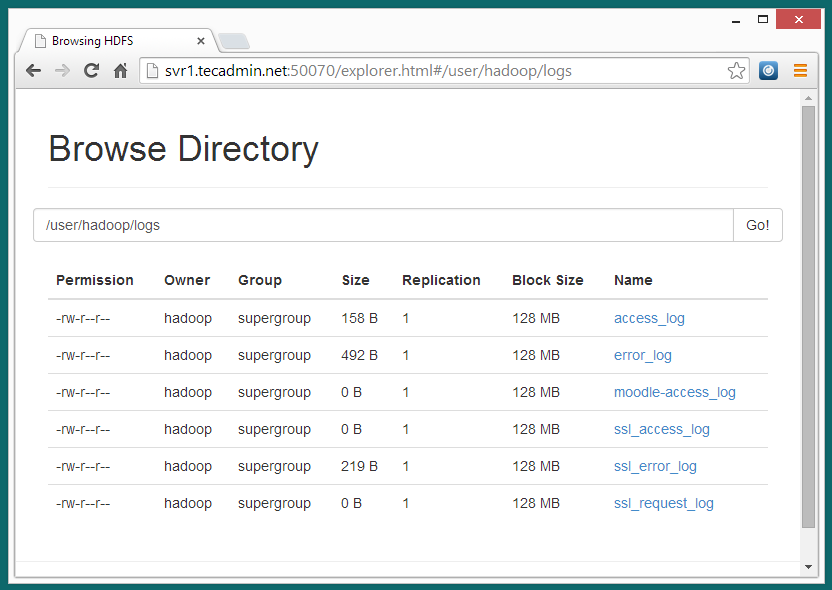
7.4 – Now copy logs directory for hadoop distributed file system to local file system.
$ bin/hdfs dfs -get logs /tmp/logs $ ls -l /tmp/logs/
You can also check this tutorial to run wordcount mapreduce job example using command line.
 Cluster Using Ansible")
72 Comments
Dear Mr Rahul
Could you kindly help me, how we can deploy the services of Single Node Cluster to multiple clients in a Lab environment.
Dear Mr. Rahul,
I am very thankful for your installation guide but could not understand how we can
Edit ~/.bashrc file to setup Hadoop Environment Variables, could you kindly help us with more screen shots please
I was stuck up at these area
4.1. Setup Hadoop Environment Variables
4.3 Resolution of host name with IP, where should we set this IP please help me
Regards
Dinakar NK
Hi Dinakar, Simply edit the ~/.bashrc configuration file and copy the settings at end of file.
echo “export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin” > ~/.bashrc
Thank You Very much nice tutorial
installed successfully but at last i m getting following error .. please reply
hdusr1@apollo-H81M-S:~/hadoop1/hadoop-2.6.5/bin$ bin/hdfs dfs -put /var/log/httpd logs
-bash: bin/hdfs: No such file or directory
Getting the error below – Is there a revised link?
[hadoop@oc8731500110 ~]$ wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
–2017-06-08 09:30:08– http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
Resolving apache.claz.org (apache.claz.org)… 74.63.227.45
Connecting to apache.claz.org (apache.claz.org)|74.63.227.45|:80… connected.
HTTP request sent, awaiting response… 404 Not Found
2017-06-08 09:30:09 ERROR 404: Not Found.
Thanks Ruchira for pointing this. I have updated tutorial accordingly.
deep@sid:~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
deep@sid:~$ chmod 0600 ~/.ssh/authorized_keys
deep@sid:~$ ssh localhost
ssh: connect to host localhost port 22: Connection refused
……
as i shown problem above.
how to solve this problem ?
I have tried everything but still I’m here.
please help me..for solving this problem..
Hi Sidharth,
Plz provide results of following commands.
$ telnet localhost 22
$ netstat -tulpn | grep 22
deep@sid:~$ telnet localhost 22
Trying ::1…
Trying 127.0.0.1…
telnet: Unable to connect to remote host: Connection refused
deep@sid:~$ netstat -tulpn | grep 22
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
deep@sid:~$
It looks OpenSSH server is not running on your system.
https://tecadmin.net/install-openssh-server-on-ubuntu-linuxmint/
Don’t change the default port.
After your guidence…..i run it again,and i get this
deep@sid:~$ ssh localhost
The authenticity of host ‘localhost (::1)’ can’t be established.
ECDSA key fingerprint is SHA256:yzHhnxJhNNct0zStIoOZfAjruW+kQHB9kjGSMXhjdEs.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added ‘localhost’ (ECDSA) to the list of known hosts.
sign_and_send_pubkey: signing failed: agent refused operation
deep@localhost’s password:
The programs included with the Kali GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Kali GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Tue Apr 18 08:49:08 2017 from ::1
-bash: $’\r’: command not found
I’m working on ” Sentiment analysis of twitter data using hadoop with hive & flume “.
So I’m following your tutorial.
And my o.s. version is KALI “Rolling-2.0,amd64”.
I am able to setup the hadoop multi node in ubuntu. but not able to setup the multi node in centos 6.6.
Where can i set the interfaces and hosts and hostname?
Can you please share the video link?
I am not able to follow step 2 because executing passwd hadoop, does ask for password.
I tried hitting just enter but then when I run ssh localhost, it keeps on asking password.
One think I noticed which is also different is the message (shows ssh2 instead of ssh):-
Public key saved to /home/hadoop/.ssh2/id_rsa_2048_a.pub
Please suggest.
Hi Rahul,
Great job!…I had some issue in running sshd ( by default, in centos, sshd needed a manual starting)…..apart from that, everything went smoothly. Your guide is really helpful.
Regards,
Palash
So it seems after I do the “set up key based ssh” section my linux machine starts to loose access to certain function’s like:
# yum
and
# ls
also
# su – hadoop
It just comes back saying -bash: yum: command not found
I’m using CentOS-7-x86_64-Minimal-1511.iso
Any ideas?
Just to follow up on this… I found the following:
# which yum
/usr/bin/which: no yum in (/usr/local/sbin:/usr/sbin:$PATH:/opt/jdk1.8.0_121/bin:/opt/jdk1.8.0_121/jre/bin:/root/hadoop/sbin:/root/hadoop/bin:/root/bin)
# which sudo
/usr/bin/which: no yum in (/usr/local/sbin:/usr/sbin:$PATH:/opt/jdk1.8.0_121/bin:/opt/jdk1.8.0_121/jre/bin:/root/hadoop/sbin:/root/hadoop/bin:/root/bin)
# which ls
alias ls=’ls –color=auto’
# which su
/usr/bin/which: no yum in (/usr/local/sbin:/usr/sbin:$PATH:/opt/jdk1.8.0_121/bin:/opt/jdk1.8.0_121/jre/bin:/root/hadoop/sbin:/root/hadoop/bin:/root/bin)
Any ideas?
Hi Nick,
It looks /usr/bin and /usr/local/bin is not added in PATH environment variable. Please use below command to add it.
export PATH=/usr/local/bin:/usr/bin:$PATH
I want to change my CentOs code that means I want to add hadoop single node cluster to this and I need to share some other?
How can I do this ??
hdfs file not found
all went well except the last step: step 7:
report01.qalab.rc1():/oracle/app/hadoop/hadoop-2.7.2 > mkdir user
report01.qalab.rc1():/oracle/app/hadoop/hadoop-2.7.2 > bin/hdfs dfs -mkdir /oracle/app/hadoop/hadoop-2.7.2/user
16/05/04 18:58:49 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
mkdir: `/oracle/app/hadoop/hadoop-2.7.2/user’: No such file or directory
can you help?
I have a error with comand $bin/hdfs dfs -mkdir /user
Error
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
mkdir: Cannot create directory /user. Name node is in safe mode.
I cannot fix error. Please help me
Thank you all !
awesome article ! read a lot of outdated ones, and went crazy these last hours trying to configure my cluster. Great thanks dude if you’re in France I owe you a beer
Hey friend,
i am newbie about hadoop i configured hadoop on vagrant ubuntu machine.i wants access hadoop web ui on browser but i unable to do so.i tried changing the core-site.xml file for hadoop ui on browser by my machine ip and different ports for ui like 9000/8020 and 50075,50070 but nothing happens.
plz help so.
Thanks in advance.
When i run wordcount job i’m getting below error
> hadoop jar wc.jar WordCount /user/hadoop/HDFSClient.java /user/hadoop/wc.out
16/02/08 12:24:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
16/02/08 12:24:56 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
16/02/08 12:24:56 INFO mapreduce.Cluster: Failed to use org.apache.hadoop.mapred.YarnClientProtocolProvider due to error: Error in instantiating YarnClient
Exception in thread “main” java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:120)
at org.apache.hadoop.mapreduce.Cluster.(Cluster.java:82)
at org.apache.hadoop.mapreduce.Cluster.(Cluster.java:75)
at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1266)
at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1262)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.connect(Job.java:1261)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1290)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314)
at WordCount.main(WordCount.java:59)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Hey,
have a question, could you please explain me, why have we created a user after installation of java, and how could the password less ssh work for ssh the localhost when i am already in the same system, or am i missing something in here.
Thanks
Thank you so much for precise instructions which makes it simple and perfect !
Great help 🙂
can i create cluster with two different os (ubuntu and cygwin on windows ) in which hadoop (same version)is installed ?
great article.. works fine
I’am using Hadoop-2.6.0 in Ubuntu 15 on a single node. When I’am starting secondarynamenode daemon, it starts without any error, but shutt down automatically as soon it is started. Even jps command is not showing it. all other deamons are running properly. I have checked secondarynamenode log file, it doesn’t show any error but a shuttdown message at the end. Please help me to resolve this
Hello Rahul!
It works on Centos 7 , JDK 8 & Hadoop 2.6
Thanks! a great tutorial.
Thanks. It worked with Centos7 and Hadoop 2.7.1
Thanks. It worked with fedora 22 and Hadoop 2.7.
The only Warning i get is below. I am not sure what it means.
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Hi Rahul,
I am trying to run my workflow on a new Yarn cluster via oozie. The job submits fine and as part of the workflow creates a scanner; the scanner is serialised and written to disk. Then during deserialising the string to a scan object I encounter the following error
Caused by: com.google.protobuf.InvalidProtocolBufferException: Protocol message end-group tag did not match expected tag.
at com.google.protobuf.InvalidProtocolBufferException.invalidEndTag(InvalidProtocolBufferException.java:94)
at com.google.protobuf.CodedInputStream.checkLastTagWas(CodedInputStream.java:124)
at com.google.protobuf.CodedInputStream.readGroup(CodedInputStream.java:241)
at com.google.protobuf.UnknownFieldSet$Builder.mergeFieldFrom(UnknownFieldSet.java:488)
at com.google.protobuf.GeneratedMessage.parseUnknownField(GeneratedMessage.java:193)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$Scan.(ClientProtos.java:13718)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$Scan.(ClientProtos.java:13676)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$Scan$1.parsePartialFrom(ClientProtos.java:13868)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$Scan$1.parsePartialFrom(ClientProtos.java:13863)
at com.google.protobuf.AbstractParser.parsePartialFrom(AbstractParser.java:141)
at com.google.protobuf.AbstractParser.parseFrom(AbstractParser.java:176)
at com.google.protobuf.AbstractParser.parseFrom(AbstractParser.java:188)
at com.google.protobuf.AbstractParser.parseFrom(AbstractParser.java:193)
at com.google.protobuf.AbstractParser.parseFrom(AbstractParser.java:49)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$Scan.parseFrom(ClientProtos.java:14555)
at org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.convertStringToScan(TableMapReduceUtil.java:516)
I googled and checked for all kinds of config errors but all my configurations such as nodename, jobtracker, etc are correctly configured. Also, the google protobuf jar is consistent across all YARN components and my code. Wondering whats going wrong?
a
-Shashank
Hi,
I need to install Hadoop 2.6.0 multi node cluster with different os configurations. I am already having a master node and one slave node both at Ubuntu 12.04. I want to add one more slave node with CentOS.
I wanted to ask is it fine?
Thanks in advance!
Hi Mr. Rahul!
First of all let me say THANK YOU for this tutorial. This is a very big help especially to a person like me who just started learning Hadoop / Bigdata.
1. I followed your guidelines without error, BUT, i can’t access the services in a browser. Giving me error “This webpage is not available”.
2. If I rebooted my machine, do I need to run the start-dfs.sh and start-yarn.sh again?
I’m using oracle virtualbox CentOS on a Ubuntu host pc.
Thank you!
Hi will you please help me to solve out this
[hadoop@bigdata hadoop]$ bin/hdfs dfs -put /var/log/httpd logs
15/05/10 10:51:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
put: Error accessing file:/var/log/httpd
Hi Vatsal,
Please make sure /var/log/httpd directory exists and have proper permission.
Hi this is really a great post, I followed it and it works! I have a follow-up question: can you post another blog for how to install Spark on this single YARN cluster which can work with the the data on hdfs on this single machine?
Hi pete, I see you’ve managed smoothly and no problems. I have followed all the steps that have been written above but I can not access ‘DataNode’ and ‘cluster and all applications’
DataNode:
http://localhost:50075
cluster and all applications:
http://localhost:8088
Please could you suggest me some solution
I am trying to install hadoop 2.6 on OEL6 using the instructions given in this blog. When I execute “hdfs namenode -format” I get the following error:
Any suggestions on what might have gone wrong?
***************************************************************
14/12/07 00:11:32 INFO util.GSet: capacity = 2^15 = 32768 entrie
14/12/07 00:11:33 INFO namenode.NNConf: ACLs enabled? false
14/12/07 00:11:33 INFO namenode.NNConf: XAttrs enabled? true
14/12/07 00:11:33 INFO namenode.NNConf: Maximum size of an xattr: 163
14/12/07 00:11:33 FATAL namenode.NameNode: Failed to start namenode.
java.lang.IllegalArgumentException: URI has an authority component
at java.io.File.(File.java:423)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.getStorag torage.java:329)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.initJourn java:270)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.initJourn EditLog.java:241)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(Nam )
at org.apache.hadoop.hdfs.server.namenode.NameNode.createName java:1379)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameN
14/12/07 00:11:33 INFO util.ExitUtil: Exiting with status 1
14/12/07 00:11:33 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at java.net.UnknownHostException
************************************************************/
export HADOOP_HOME=/home/hadoop/hadoop
I didnt understand the above statement. When you create a user hadoop, a folder will be created in home directory. What the purpose of second hadoop?
cd $HADOOP_HOME/etc/hadoop
There is no hadoop folder in etc directory.
I am confused because etc comes under the supervision of root user rather than hadoop user.
Hi, I am trying to run wordcount example. But it is getting stuck at ACCEPTED state.
It is not going into RUNNING state.
Any help appreciated. I have followed the tutorial exact. But using 2.6.0 instead of 2.4.0
Hello,
We have followed the given steps for centos 6.5 and hadoop2.5.0. All the dameons get started but still the namenode is not visible on the browser using port no: 50070, error is displayed: “Connection to server sar166.co.com failed”. Please can you suggest some solution!!!
Thank You.
The port #9000 must be busy.
2 options:
– you can change the listening port on the `core-site.xml` file
– or you can stop the over application listening to #9000 (php-fpm ?)
Once it is done, just run `stop-dfs.sh` followed by & `start-dfs.sh`
Dear
How I change command from
-Old 64 bit
-1.7.0.51
-rhel-2.4.5.5.el7-x86_64 u51-b31
-(build 24.51-b03,mixed mode)
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el7_0.x86_64/jre
What command change dorectory
My VM ware java version
-1.7.0.45
-rhel-2.4.3.3.el6-i386 u45-b15
-build 24.45-b08,mixed mode,sharing
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6_0.i386/jre
please help advisor because I am beginner CENT OS and HODOOP
Best regards
Dear Rahul
How I set again cloud you advisor
I used
-CentOS-6.5-i386-bin-DVD1
java -version “1.7.0.45”
OpenJDK Runtime Environment (rhel-2.4.3.3.el6-i386 u45-b15)
OpenJDK Client VM (build 24.45-b08,mixed mode,sharing)
after that I can not run hadoop HOW set I get it to run
I used
-CentOS-6.5-i386-bin-DVD1
java -version “1.7.0.45”
OpenJDK Runtime Environment (rhel-2.4.3.3.el6-i386 u45-b15)
OpenJDK Client VM (build 24.45-b08,mixed mode,sharing)
after that I can not run hadoop how I get it to run
Dear Sir
after I start hadoop can not run please help advisor
-used hadoop-2.5.1
-java ‘ ok
-but have message below
/home/hadoop/jhadoop-2.5.1/bin/hdfs:line 262: /user/lib/jvm/java-1.7.0-openjdk-1.7.0.65-2-5.1.2.el7_0x86_64/jre/bin/java: N o such file or directrory
Hi,
Please make sure you have configured JAVA_HOME correctly.
Hi, This one is a great article. I followed many other blogs for this problem. But none of them worked. This one simply worked with no error.
But i have a little problem.
I have installed hbase standalone mode.
Now i want hbase to use hdfs. So in hbase-site.xml file i added this:
hbase.rootdir
hdfs://localhost:9000/hbase
dfs.replication
1
But its giving error and not working. Any reason why its not working? I copied the same configuration of yours during my hadoop installation.
Regards
Jay
Hi Rahul,
Thank for this article.
For me everything worked as I followed through this article. But at the last I could not get details of my datanode when I browsed http://server1.com:50075/. The browser says ‘Unable to connect’
What could be the problem or what mistake I might have done? Please help.
Nice article. I Managed ot get as far as starting the scripts and ran into problems that required havking the scripts and then got a warnign that ssh could not regonise the host name but start-dfs.sh and start-yarn.sh eventually ran ok, but I could not access hadoop in the browser and wnhen trying to ls the filesystem I get an error
hdfs dfs -ls
Exception in thread “main” java.lang.RuntimeException: core-site.xml not found
However this got me along way forther
Hi Rahul,
Thanks for taking the time to write up this guide, it was very helpful.
Hi Rahul
Thank you for sharing this with us. I followed your steps in installing hadoop 2.4 on Centos Vritual Machine. I have an Hbase running on my mac machine, I get connection refused error when hbase tries to connect.
Here is my setting in core-site.xml
fs.default.name
hdfs://localhost:54310
and on Hbase: hbase-site.xml
hbase.rootdir
hdfs://localhost:54310/hbase
I can telnet onto the port 54310 from the VM but not from a remote machine, i.e my local macbook which is running the virtual machine. Looks like the port is closed to remote client. I have disabled firewall but it didn’t help.
Any idea?
Regards,
Ayache
Dear Rahul,
thanks for the tutorial, why
“hadoop/etc/hadoop/hadoop-env.sh”
“hadoop/etc/hadoop/hadoop-env.sh” E212: Can’t open file for writing
cant be written?
thanks.
frankie
Hi Frankie,
Please check if hadoop user has proper privileges on this file
Dear Rahul,
Thanks for all the steps. Please update the mapred-site.xml to mapred-site.xml.template.
Also, please update the testing the setup.
Thanks,
Sachin
Very good article,
Two issues,
First exit; ssh localhost will not work for public/private key
Should be ssh localhost; exit
Second
hadoop path shoudl be added for bin directory, thus
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Other than this, everything worked flawlessly and hadoop is up and running perfectly…
Thanks much
Thanks Sasha,
We have updated article accordingly.
Rahul, wonderful article!!!
Need to know few things and appreciate your feedback on this;
1. Used RHAT 6.3 with Java 1.7/Hadoop 2.6.0
2. Able to run the Name Node and Data Node
Issues:
1. Cannot get the web access for the namenode (tried both 54310, 9000, 50070 with the IP address in front: http://host_IP:port_address)
2. How do we distinguish which hadoop source file should be used for the namenode Vs datanodes?
3. Where do we distinguish them(namenode Vs datanode) during installation?
4. Not able to get to run “jps”?
Please help.
Thanks,
Yash
1. Cannot get the web access for the namenode (tried both 54310, 9000, 50070 with the IP address in front: http://host_IP:port_address)
answer :
you can check your iptables and allow that port (54310, 9000, 50070). i try it and it works well.
Agreed.. 🙂
Dear Rahul,
This article was very helpful for me. I hope that you will continue…..
Thank you.
Great article but here is a script that also install hbase, hdfs, and a number of other resources
http://stevemorin.blogspot.com/2014/06/setup-single-node-hadoop-2-cluster-with.html?view=classic
When are you publishing next part of this article? I loved this and I am waiting to see how will you test your setup by running some example map reduce job.
hi Rahul i follow is i run the pi jops some error came how to solue this problam pls
test@p2 hadoop-2.4.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.0.jar pi 5 100
Number of Maps = 5
Samples per Map = 100
14/05/22 19:24:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Starting Job
14/05/22 19:24:03 INFO client.RMProxy: Connecting to ResourceManager at /127.0.0.1:8032
14/05/22 19:24:04 INFO input.FileInputFormat: Total input paths to process : 5
14/05/22 19:24:05 INFO mapreduce.JobSubmitter: number of splits:5
14/05/22 19:24:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1400761600720_0003
14/05/22 19:24:06 INFO impl.YarnClientImpl: Submitted application application_1400761600720_0003
14/05/22 19:24:06 INFO mapreduce.Job: The url to track the job:
14/05/22 19:24:06 INFO mapreduce.Job: Running job: job_1400761600720_0003
hi i run the some pi jps some error how to find
[test@p2 hadoop-2.4.0]$ jps
10476 SecondaryNameNode
10296 DataNode
10201 NameNode
10762 NodeManager
11086 Jps
10661 ResourceManager
[test@p2 hadoop-2.4.0]bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.0.jar pi 10 100
Number of Maps = 10
Samples per Map = 100
14/05/22 13:18:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
14/05/22 13:18:03 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
java.io.IOException: Failed on local exception: com.google.protobuf.InvalidProtocolBufferException: Protocol message end-group tag did not match expected tag.; Host Details : local host is: “p2.in.krs.na/67.215.65.132”; destination host is: “0.0.0.0”:8032;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764)
at org.apache.hadoop.ipc.Client.call(Client.java:1414)
at org.apache.hadoop.ipc.Client.call(Client.java:1363)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at $Proxy16.getNewApplication(Unknown Source)
at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.getNewApplication(ApplicationClientProtocolPBClientImpl.java:193)
at sun.reflect.GeneratedMethodAccessor2.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:616)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:190)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:103)
at $Proxy17.getNewApplication(Unknown Source)
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.getNewApplication(YarnClientImpl.java:165)
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.createApplication(YarnClientImpl.java:173)
at org.apache.hadoop.mapred.ResourceMgrDelegate.getNewJobID(ResourceMgrDelegate.java:179)
at org.apache.hadoop.mapred.YARNRunner.getNewJobID(YARNRunner.java:230)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:357)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:416)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1548)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303)
at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:306)
at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:616)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:72)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:145)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:616)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
Caused by: com.google.protobuf.InvalidProtocolBufferException: Protocol message end-group tag did not match expected tag.
at com.google.protobuf.InvalidProtocolBufferException.invalidEndTag(InvalidProtocolBufferException.java:94)
at com.google.protobuf.CodedInputStream.checkLastTagWas(CodedInputStream.java:124)
at com.google.protobuf.AbstractParser.parsePartialFrom(AbstractParser.java:202)
I’am also getting the same error.Please tell me how you solved it…. Thanks.
Dear Garima,
Do check Java library which have to required for Installatio of Hadoob.
hi,
This is Anbu.
May i know your skype id and available time.
i have some doubts in mapreduce.
Thanks,
Anbu k.